
総務省の都道府県・市区町村別統計表は 5 年毎に施行される国勢調査を元に作成されており,日本の人口統計の基本となる資料です.
今回はこの資料を元に人口と人口増減率を散布図にするため第一正規形にします.
書式のダウンロード
検索条件は以下の4つです.
- 「ファイル」
- 「国勢調査」
- 「都道府県・市区町村別統計表(国勢調査)」
- 「都道府県・市区町村別統計表(男女別人口,年齢3区分・割合,就業者,昼間人口など)」
最後の男女別人口,年齢3区分・割合,就業者,昼間人口は不要かも知れません.この検索条件を外しても同様の結果が得られます.
ダウンロードできるファイルは「都道府県・市区町村別統計表(一覧表)」で 4 個,平成 12 年(2000 年),平成 17 年(2005 年),平成 22 年(2010 年),平成 27 年(2015 年)です.
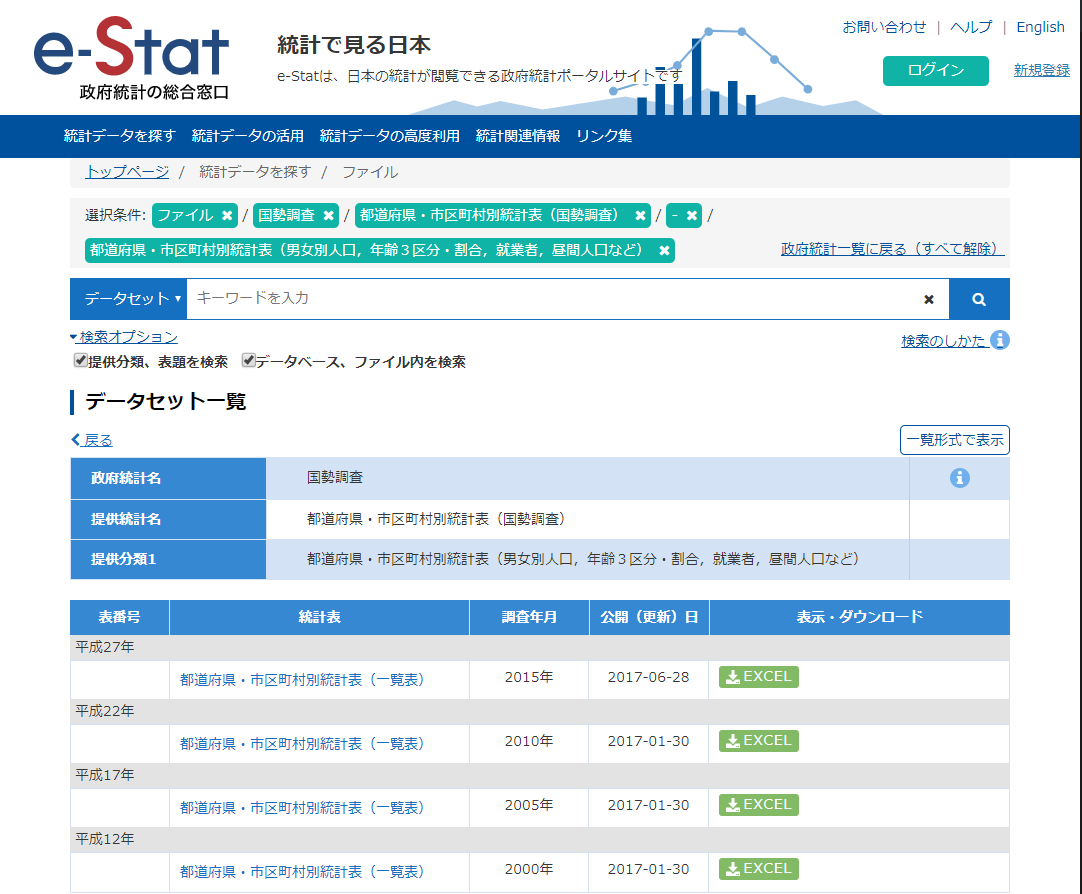
タイトル名の確認と取捨選択
項目の概観
それぞれのファイルを開くと,各ファイルごとに調査した項目が異なります.
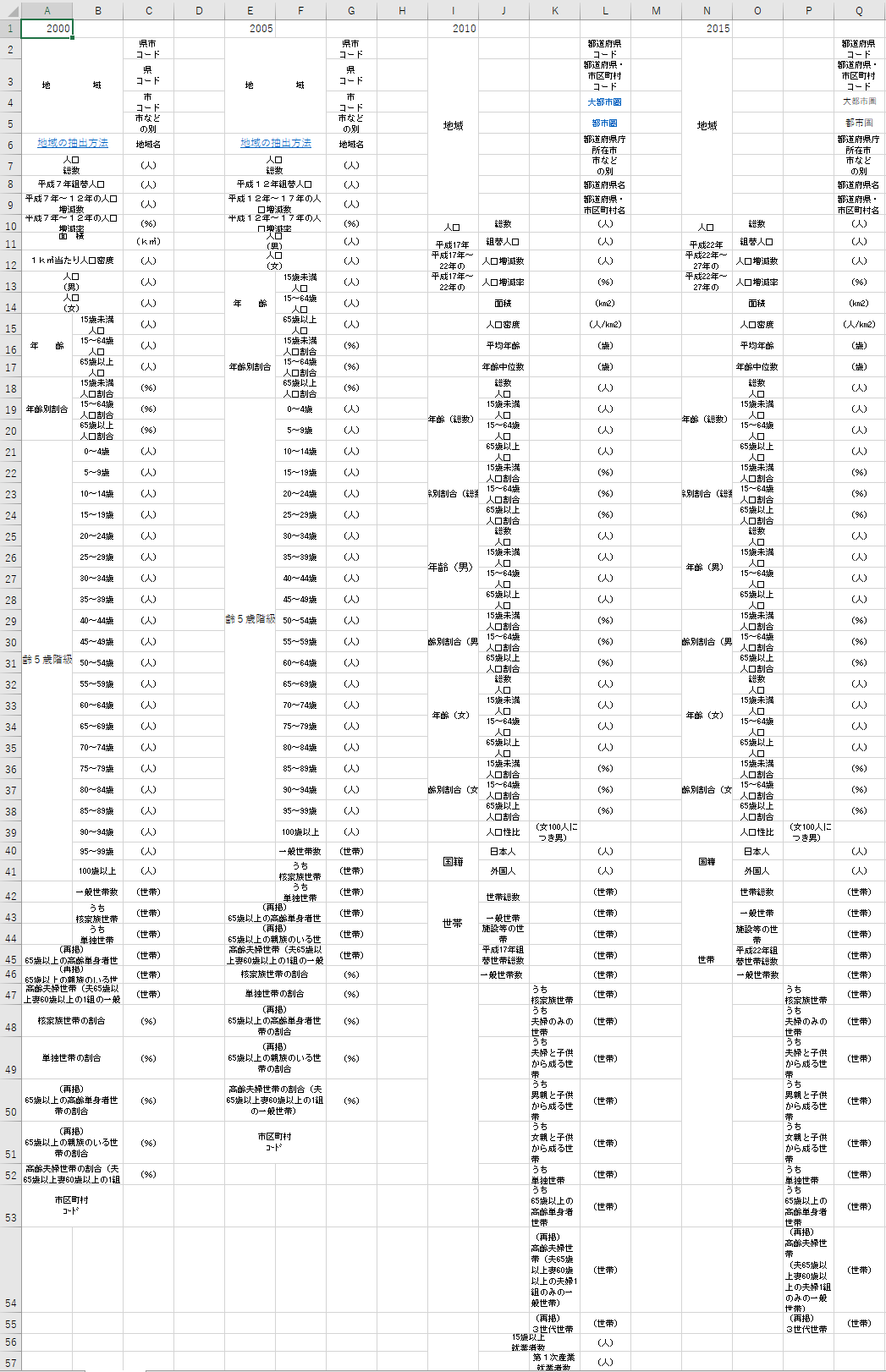
今回は一つのテーブルを作ることが目的なので,全てに共通した項目以外は削除する方針とします.
共通項目の抽出
まずは機械的な作業から.以下のリストに従ってワークシートを修正していきます.
- セル結合の解除
- 結合解除に伴う値の補完
- 罫線の削除
- 項目の列を揃える
セル結合の解除
ワークシートのすべてのセルを選択し,コントロールキーと1をタイプして「セルの書式設定」を開きます.
「配置」タブを選び,「文字の制御」の「折り返して全体を表示する」「セルを結合する」を2回クリックしてチェックを外します.
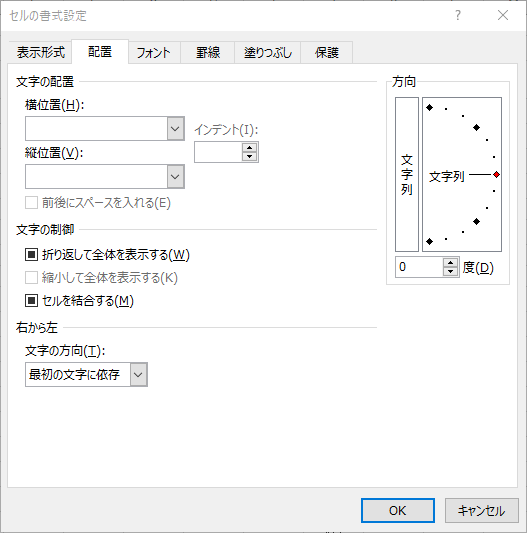
さらに「文字の配置」の「横位置」と「縦位置」が空白になっているので,それぞれ「標準」「中央揃え」を選びます.
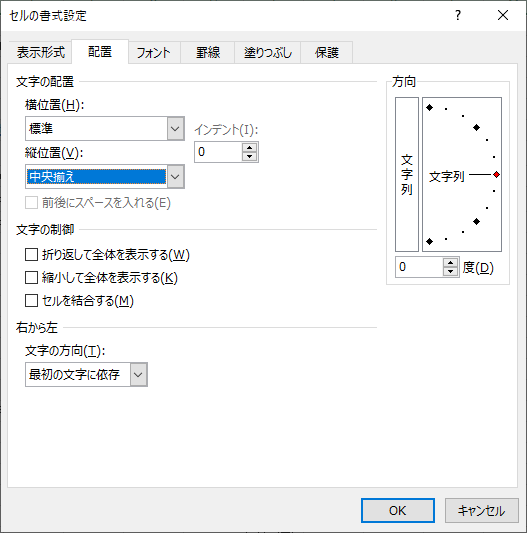
単なる位置合わせのためのスペースが入力されていることが分かります.これは検索の際に邪魔になるので「検索と置換」で一括削除します.
ついでにセル内改行も削除します.「検索と置換」で「検索する文字列」にコントロール+Jとタイプします.ここでは分かりやすいように表示していますが,実際のダイアログでは何も表示されません.
127 件が削除されました.
市区町村コードが主キー
ワークシート全体を見渡し,全ての年に共通の項目が何か確認します.中でも市町村を識別する項目が何かは重要です.
それは「市区町村コード」です.「市区町村名」は同名の市区町村が存在する可能性があります.市区町村コードは5桁の数字からなり,前半 2 桁は「都道府県コード」を示し,後半 3 桁が「市区町村コード」を示しています.
この市区町村コードはテーブルの主キーとなる項目です.他のいずれの項目も主キーにはなれません.これは自明のことです.
コードの割り振り方に問題のある可能性もありますが,現時点ではこれで自治体のシステムは運用されています.
さて,それぞれのファイルのどこに市区町村コードがあるか確認しましょう.

比較的上位に記述されていることが分かります.市区町村コードがわかれば市区町村名,ひいては都道府県名も自動的に分かるはずなのですが,ここではそこまで正規化を進めないので,都道府県コード,市区町村コード,市区町村名,都道府県名を残すことにします.
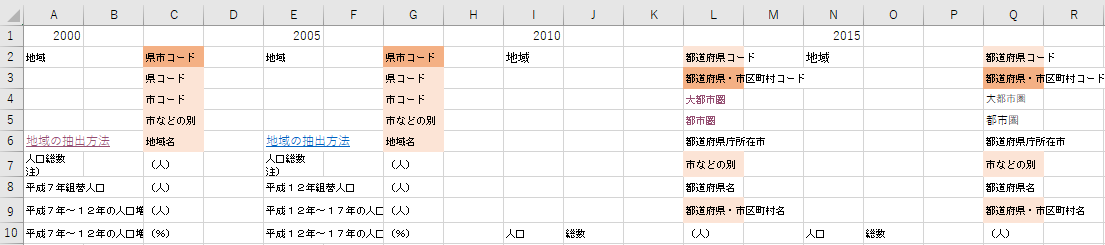
これらの項目は BI ではディメンションと呼ばれ,分類のための次元となります.
人口総数,組換人口,人口増減数,人口増減率
次に人口統計の基本となる数値が記述されている項目を探します.下図の緑色で示したセルが該当します.
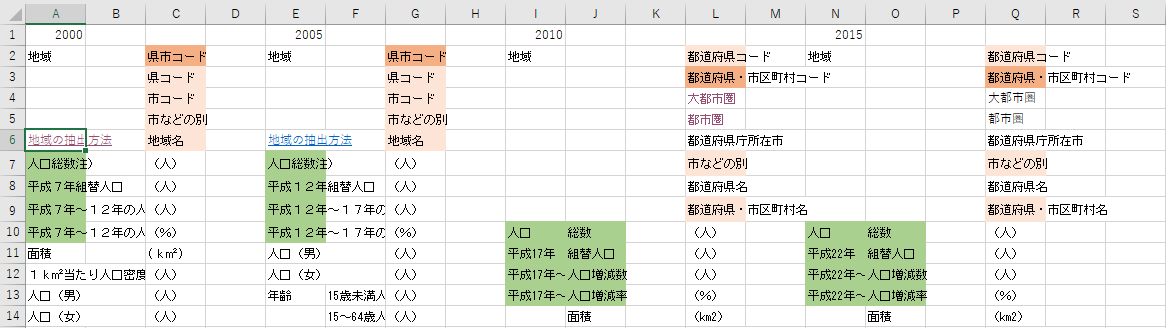
2000 年と 2005 年は一つのセルに記述されていますが,2010 年と 2015 年は二つのセルに分割されています.これは良くありません.
2005年までは年齢5歳階級別人口のみ,2010年以降は男女別の生産年齢人口とそれ以外に簡素化
国勢調査の元データを探せばあるはずですが,このファイルから抽出できるのは生産年齢人口とそれ以外のみです.年齢 5 歳階級別人口は生殖可能年齢の女性を抽出できるため,厳密な人口予測に必要なのですが別のファイルを当たる必要がありそうです.
それはともかく,4つのファイルから共通して抽出できるのは 15 歳未満人口,15-64 歳人口,65 歳以上人口です.
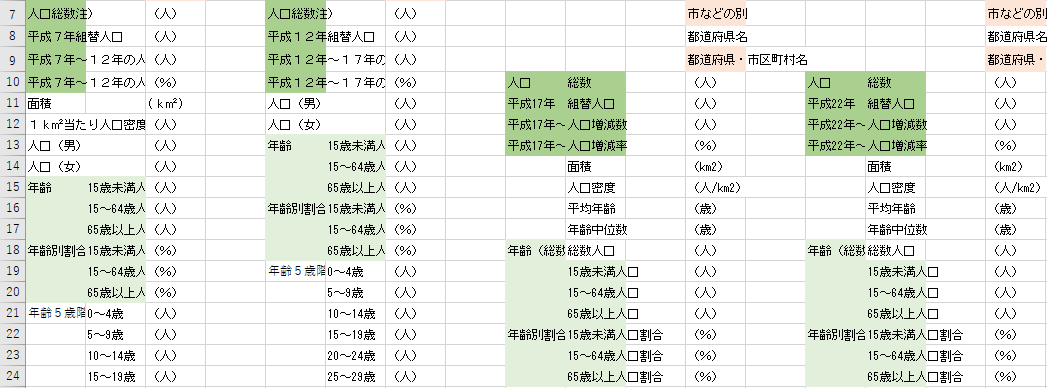
2005年までは世帯は核家族と単独のみ,2010年以降は詳細な家族構成
2005 年までは「一般世帯」の内訳として「核家族世帯」と「単独世帯」があるのみでしたが,2010 年以降はさらに「夫婦のみ」,「夫婦と子供のみ」,「男親と子供のみ」,「女親と子供のみ」,「65 歳以上の高齢単身者世帯」,「高齢夫婦世帯」,「3世代世帯」に細分化されています.
さらに「施設等の世帯」が新設されており,それに伴って「組替世帯総数」も併設されています.
そろそろ見にくくなってきました.切り取り,貼り付けで高さを揃えましょう.
4 つのファイルに共通していた項目は「一般世帯数」「核家族世帯数」「単独世帯数」「高齢夫婦世帯数」「65歳以上の高齢単身者世帯数」の 5 項目でした.
2005 年までは高齢化に焦点が当たっており,2010 年以降は少子化に焦点が当たっている印象です.
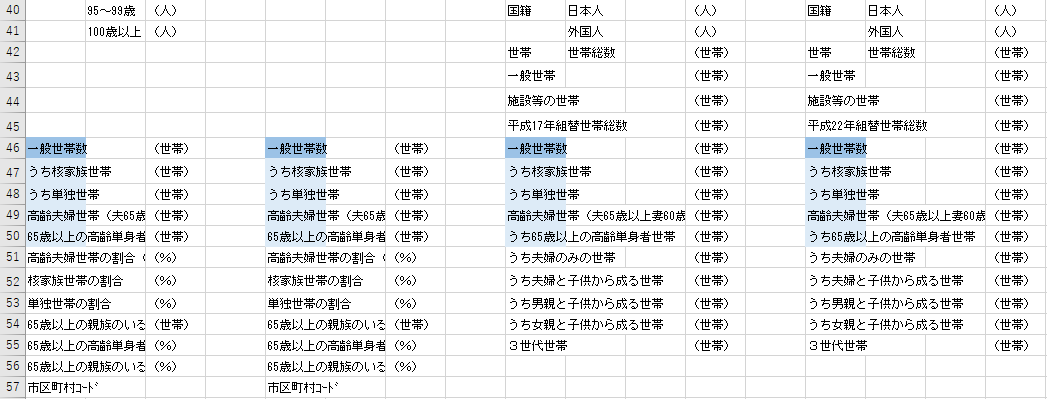
共通項目を揃える
セルの切り取り,貼り付け・切り取った範囲の挿入を用いて整形します.結果をお見せします.「(再掲)」,「注)」,「うち」などの語句は削除してあります.

さらに()内の断り書きを削除し,空白の項目を追加するなどして項目名を整理します.
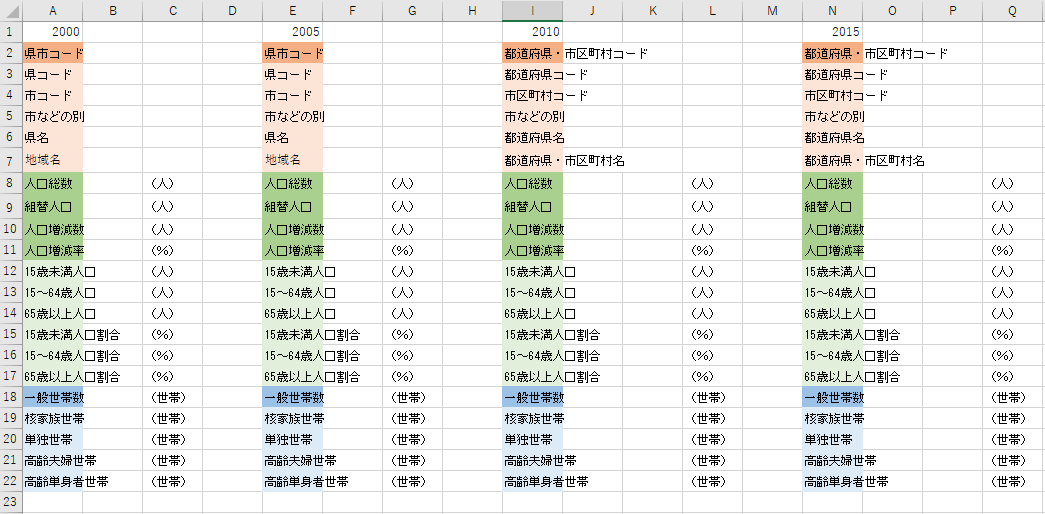
最終的に下図のような項目が残ることが分かります.「年」と「市区町村コード」の組み合わせが主キーとなります.
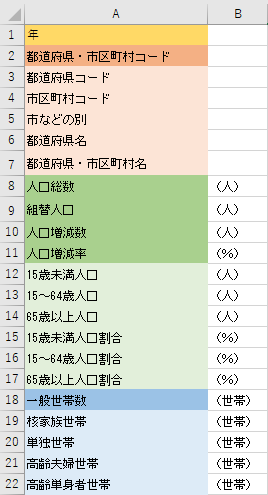
各ファイルの列を削除して整理
前章に従って各ファイルの列を削除し,列の順番を入れ替えます.「年」の列がないため,列を挿入してコピー貼付けします.